Why FiTL Over Current/General Search Algorithms
Advantages Over a General Search Algorithm
Why develop and/or learn an entire language just to do a more specific search?
In my experience with typical applications (especially ones on the web), search works ever so slightly differently on each site. While the inconsistency is usually the biggest problem, the leeway when it comes to searching/filtering down a table can get frustrating if not confusing. While search acceptance is based on the use case of the application, underdeveloped applications (IE old product pages) may provide a search that is too strict and will not catch many obvious cases.
Many modern applications (Spotify...) however may provide a search that either catches not only too many cases, or also catches strange cases where you are left wondering how it got that result from that search query. For example, why am I getting "the Way You Make Me Feel" by Michael Jackson and "How Do I Make You Love Me" by The Weeknd from the query: "you the make"? "the" is not even in the title "How Do I Make You Love Me"?
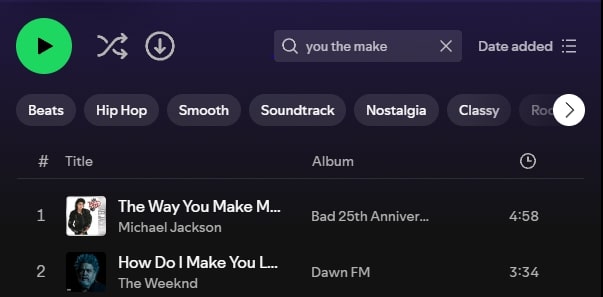
The Simple answer is that it doesn't get just search for exact (or close matches) in song titles, rather it super fuzzy searches within all fields. An algorithm that works for the most part most of the time, but is very difficult to get specific, especially when I just want to quickly make a temp playlist of all my liked songs from a specific artist right before I hit the road.
-- Spotify Rant Over --
This is not something specifically directed at Spotify as many other modern services (YouTube, Reddit, Genius.com, etc, all share similar problems), Spotify is just where I filter tables data the most.
So how does FiTL aim to fix the overall issue?
- FiTL allows the same kind of quick fuzzy filtering, but also allows for more specific filtering
- FiTL's syntax will stay the same across applications (granted they implement the library), leaving less room for guessing and unexpected behavior for searches and filtering
- Compared to writing your own filtering algorithm, FiTL is more efficient to implement and more efficient to run, since the library is either compiled into raw binary, or into web assembly keeping it lightweight and responsive
- If all else, FiTL can run along side your own search/filtering algorithm by allowing users to further filter down search results